Data Aggregation Methods
Last Updated on 3. May 2023 by Martin Schuster
If an oracle retrieves its data from multiple data sources, it needs to aggregate them. In this topic, you will learn how blockchain oracles detect outliers and aggregate data.
Outlier Elimination
The first step is to detect and eliminate outliers. Outlier detection is important to keep the data reliable. But since oracles don’t know what data is right or wrong, they can only apply very rough measures.
The most straightforward approach is to cut off the n lowest and n highest values from the data set. This is often used in jury decisions in sports.
Let us consider the following example. There are ten data sources. Each of them reports one value. We want to set n = 1.
| data source | value |
| 1 | 5 |
| 2 | 3 |
| 3 | 8 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 5 |
| 9 | 1 |
| 10 | 3 |
First, we sort the values.
| data source | value |
| 9 | 1 |
| 2 | 3 |
| 10 | 3 |
| 4 | 4 |
| 1 | 5 |
| 5 | 5 |
| 8 | 5 |
| 6 | 6 |
| 7 | 7 |
| 3 | 8 |
Then, we eliminate the highest and lowest value. These are 1 (reported by data source 9) and 8 (reported by data source 3).
The resulting table looks like that:
| data source | Value |
| 2 | 3 |
| 10 | 3 |
| 4 | 4 |
| 1 | 5 |
| 5 | 5 |
| 8 | 5 |
| 6 | 6 |
| 7 | 7 |
The threshold n can be given absolutely or depending on the number of sources.
Another similar approach is to calculate quantiles and eliminate them. A common threshold is the first quartile and third quartile. Everything below or above is ignored in the following aggregation step. Another way of eliminating outliers is to give an upper and lower bound in which the reported values must lie. This is useful to eliminate nonsense data like negative sizes or prices.
When calculating the quartiles, we need to sort the values first and calculate the cumulative percentage.
| data source | Value | cumulative percentage |
| 9 | 1 | 0.1 |
| 2 | 3 | 0.2 |
| 10 | 3 | 0.3 |
| 4 | 4 | 0.4 |
| 1 | 5 | 0.5 |
| 5 | 5 | 0.6 |
| 8 | 5 | 0.7 |
| 6 | 6 | 0.8 |
| 7 | 7 | 0.9 |
| 3 | 8 | 1.0 |
There are different methods how to determine the exact value of a quartile that yield different results. Here, we use the cumulative percentage to determine the quartiles.
The first quartile consists of all values that receive a cumulated percentage of at least 25 % (0.25). To achieve this, we need to include 1, 3, and 3.
The third quartile consists of all values that receive a cumulated percentage of at least 75 % (0.75). This comprises the values 1, 3, 3, 4, 5, 5, 5, and 5.
Since we want to ignore all values below the first quartile and above the third quartile, we get the following table:
| data source | value |
| 4 | 4 |
| 1 | 5 |
| 5 | 5 |
| 8 | 5 |
Besides those simple methods, there are more sophisticated outlier detection mechanisms like k-nearest neighbor, support vector machines, hidden Markov models, etc. However, they are difficult to perform on a smart contract.
Value Aggregation
After eliminating outliers, the oracle has to condense all data into a single value. Again, we have different options here:
- Mean: average
- Median: the number in the middle of the sorted values
- Mode: the most often repeated number in our data set
The following example shows the calculation of average (mean), median, and mode with the data from our cleaned table.
| data source | value |
| 2 | 3 |
| 10 | 3 |
| 4 | 4 |
| 1 | 5 |
| 5 | 5 |
| 8 | 5 |
| 6 | 6 |
| 7 | 7 |
Average = (3+3+4+5+5+5+6+7)/8 = 4.75
Median = (5+5)/2 = 5
Mode = 5
The mode can be considered as a majority voting. [1] However, it can be difficult to determine, if there is no single most value.
On-Chain Aggregation
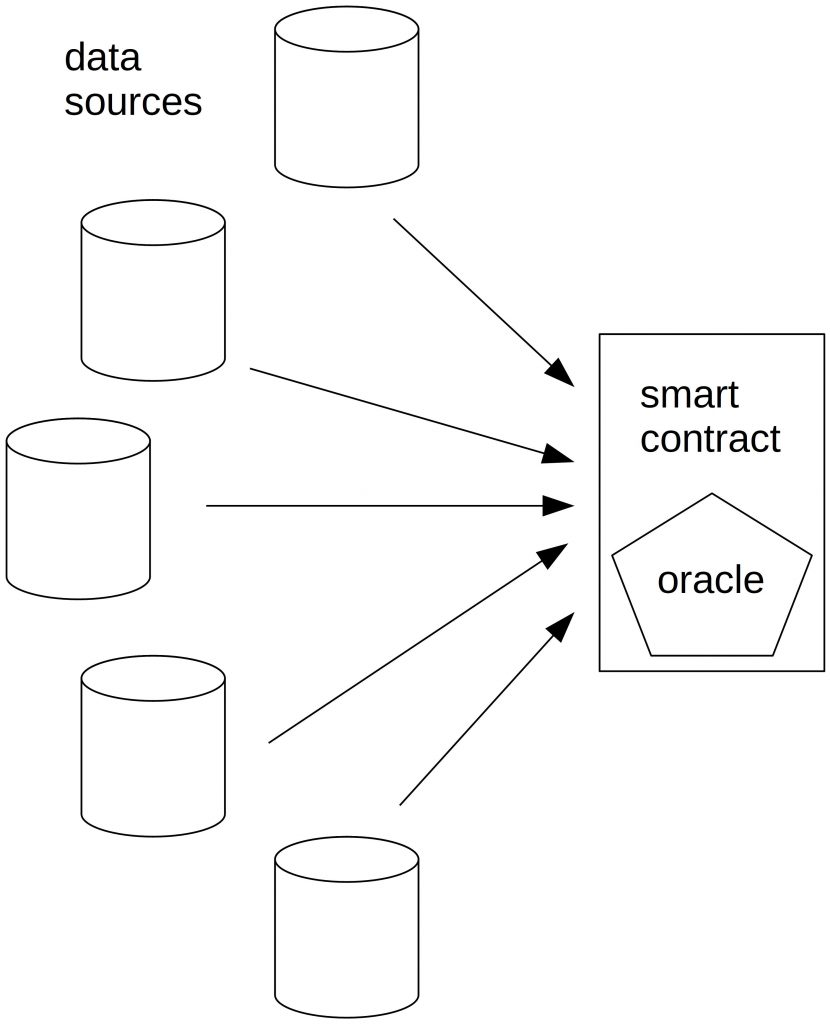
In an on-chain aggregation scheme, all data sources send their data to a smart contract. To mitigate the last actor problem, oracles could introduce a commit-reveal scheme with a deposit that is burned if the data source doesn’t report in time.
Such an on-chain aggregation scheme is independent of a centralized authority. But it is expensive since every reporter has to create a transaction and pay for it. This becomes more severe if a commit-reveal scheme is used, and each reporter has to make at least two transactions.
Off-Chain Aggregation
Oracles can decide to collect and aggregate data off-chain and only report the result to their smart contracts. The first way to do this is that the data sources report to the oracle. The data oracle cleans and aggregates the data. After it is finished, it sends the data to the smart contract.
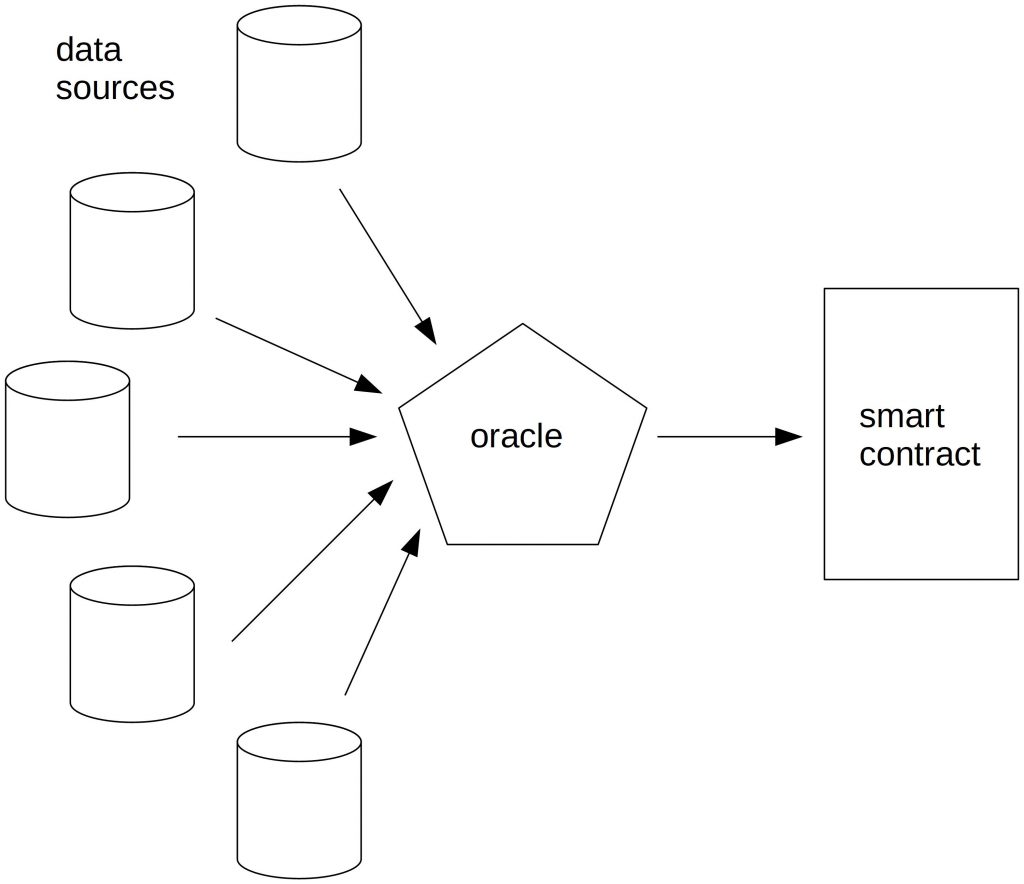
The problem is that neither the reporter nor the data consumer can be sure whether its data got aggregated correctly unless the raw data is provided to the smart contract.
To avoid this uncertainty, reporters can coordinate themselves using threshold signatures like Schnorr signatures. To create a threshold signature, you need at least k out of n participants. This makes the signature resilient against not responding data sources.
In this setup, reporters exchange their values and aggregate them to a value A. Then, every data source signs the value A. If a majority (k out of n) of data sources signed the same value A, it is considered as correct. In the next step, this value A is sent to the smart contract.
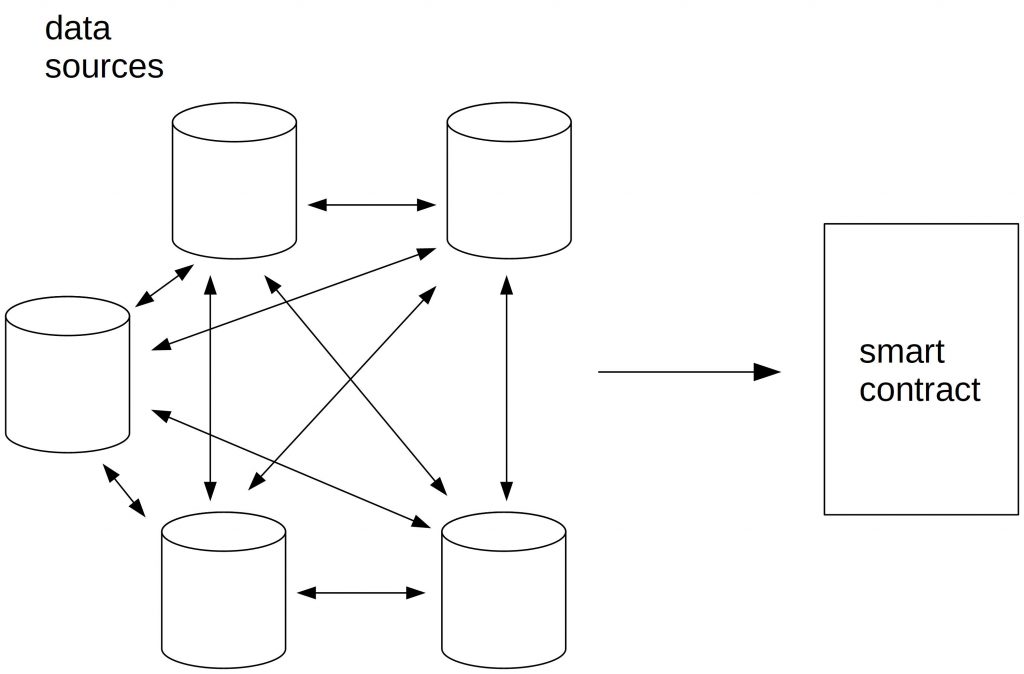
However, the tricky task is to provide an infrastructure where all oracles can exchange their values and signatures. And finally, one participant has to create a transaction and send the signature to the blockchain. This requires a centralized authority again.
Besides the issue regarding the communication infrastructure, freeloading is a problem too. Here, reporters can simply copy the data from other reporters and thus save data retrieval costs.

 Register
Register Sign in
Sign in