Merkle Trees – Data Representation in Bitcoin
Last Updated on 3. May 2023 by Martin Schuster
So far, we assumed a block consists of transaction data and some header data like timestamp, nonce, difficulty, etc.
Those data form the input of the hash function with which the block hash is calculated. However, the transaction data is packed in a data structure called Merkle tree. Instead of every transaction only the root of this tree (or top hash), the Merkle root, is taken as hash input.
For every block, a new Merkle tree is created taking those transaction into account that are part of the block.
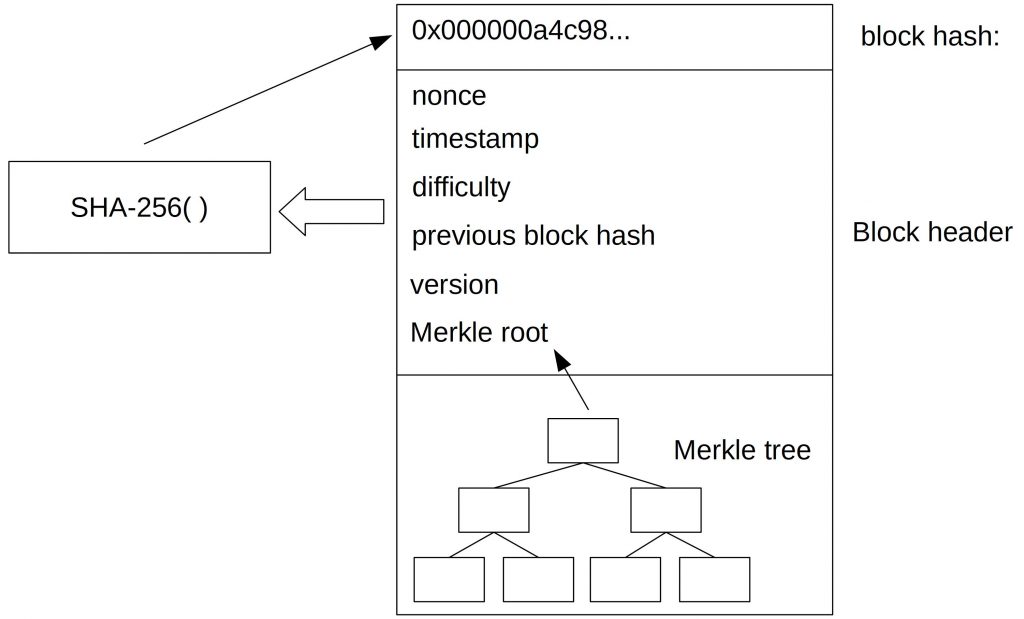
In the figure above you can see that the Merkle root becomes part of the block header.
In the following, you will learn how to construct a Merkle tree. A Merkle tree is (typically) a binary hash tree where each node has two child nodes.
You can try out our tool for Merkle Trees here.
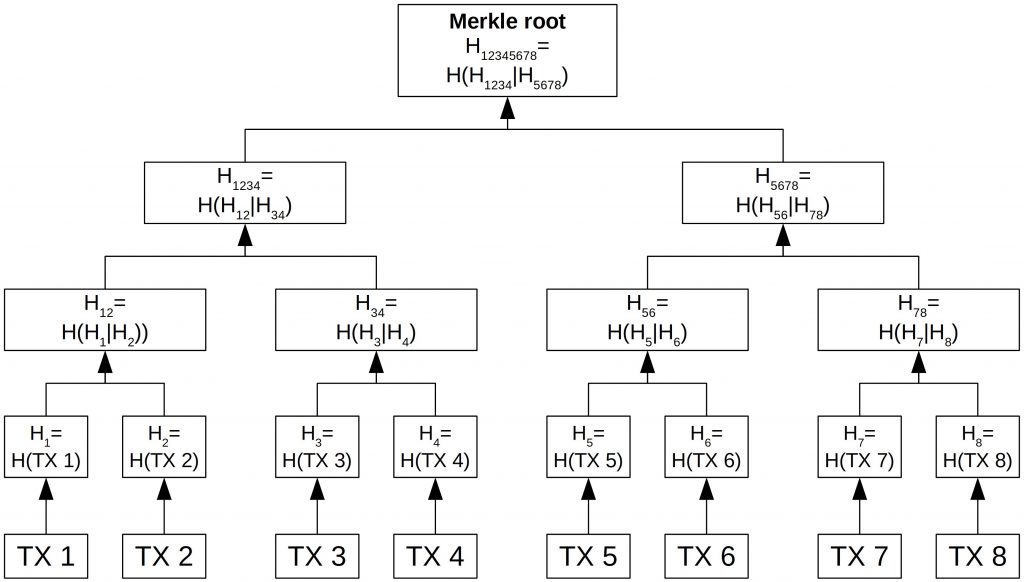
Construction starts from the bottom with the leaves. They contain the plain transaction data. Then they are individually hashed (H=H(TX1)). Those hashes are then concatenated pairwise. And each pair is the input for the next hash. This pairwise hashing goes up until only one hash is left. This is the Merkle root or top hash of the Merkle tree.
The figure below shows the construction of a Merkle tree with eight transactions.

 Register
Register Sign in
Sign in