Consensus
Last Updated on 20. March 2023 by Martin Schuster
Suppose Bob creates two rivaling transactions like in the figure Double-spend (in Topic User Verification – Addresses). In that case, the network needs to decide which transaction is valid and which one is to be ignored.
Therefore, we create first a data structure called a blockchain.
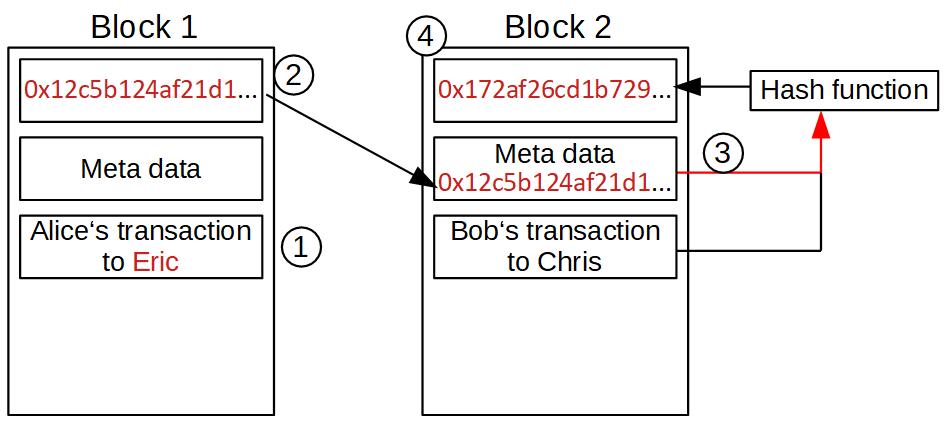
We include the transaction from Bob into a file, add a few metadata (like timestamp, a difficulty value, nonce, etc. For now, it is not important to understand what they are good for. We will have a look at some of them later on) and call this a block.
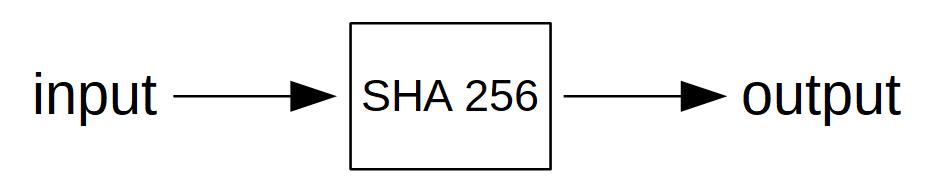
Then we add a so-called block hash to this block. A hash function is a mathematical function that takes an input of arbitrary length and condenses it to an output with a fixed length. There are many hash functions out there. In Bitcoin, we use a hash function called SHA-256.
You can play with some hash functions here:
Simple Hash Calculator
The output looks pretty random to us, and that’s good. There are three important properties:
- If you use the same input, you always get the same output.
- It is impossible to retrieve the input back from the output (one-way function).
- If you change the input even just a tiny bit the output (hash) changes completely.
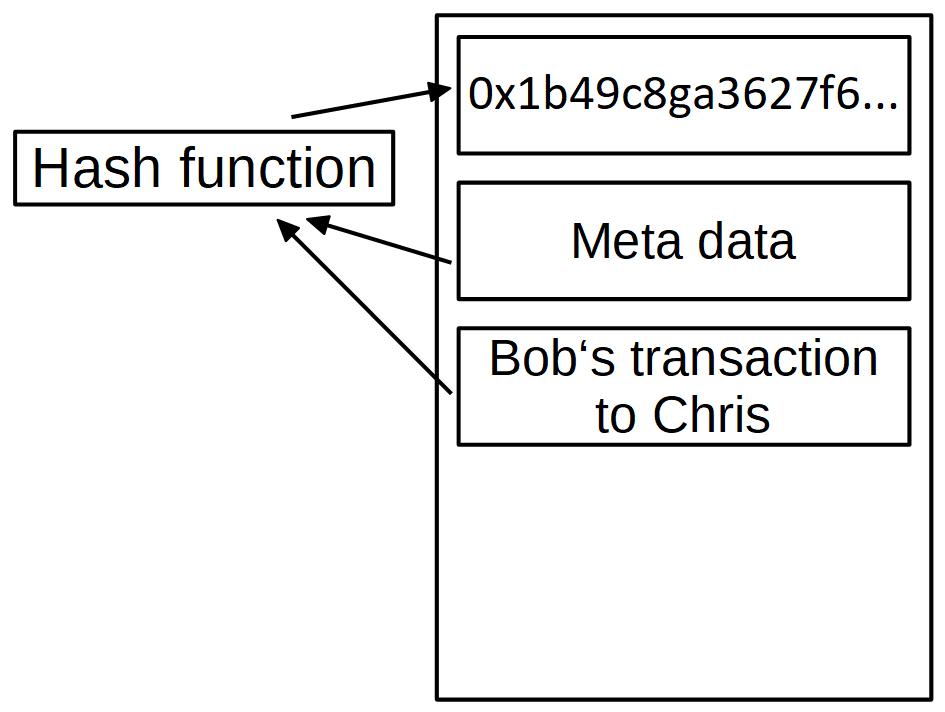
The input of our hash function is the metadata and the transaction data. Our output hash might look like this: 0x1b49c8ga3627f6…
This hash we write in the head of our block and call it block hash. You will understand why we need this in the upcoming sections.
It is possible to write more than one transaction in each block. This makes the whole process more efficient. But for clarity reasons, we are content with only one transaction.
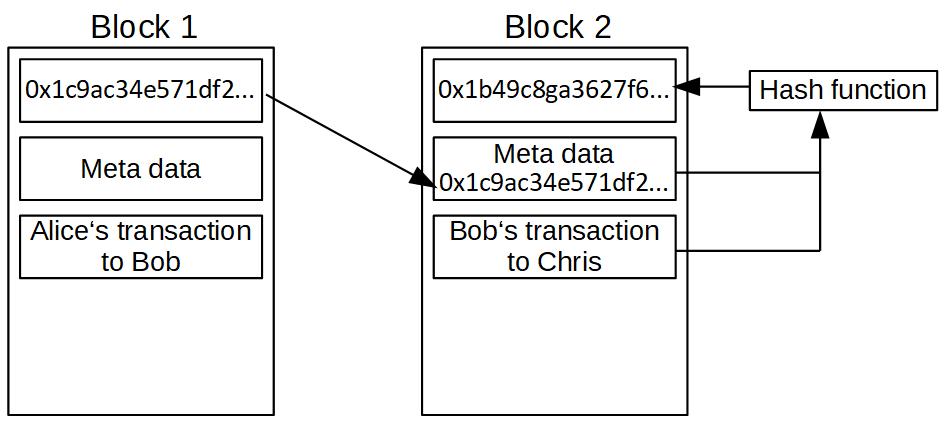
If we make a little change to the transaction data, the resulting hash changes completely. How can we apply this to our advantage? We can build a chain of blocks that are connected. Therefore we take the hash of the previous block into our set of metadata of the following block and use it as part of the input in our hash function. It looks like this:
If you wonder what hash goes into block 1 (the first block at all), in Bitcoin, it is 0.
So, what would happen if someone changes the data in block 1?
- The data in the block change and with it the input to our hash function.
- The block hash of block one changes subsequently.
- This would mean that the metadata in block 2 change and
- with it the block hash of block 2.
The link between block 1 and 2 will be broken if block 2 doesn’t get updated. So, this is an easy way to detect changes in the data structure.
In this data structure, block 2 points to block 1 by referencing its block hash. And block three would point to block two by using its block hash and so forth. That’s why we call this hash pointer. Usually, it is depicted like this:
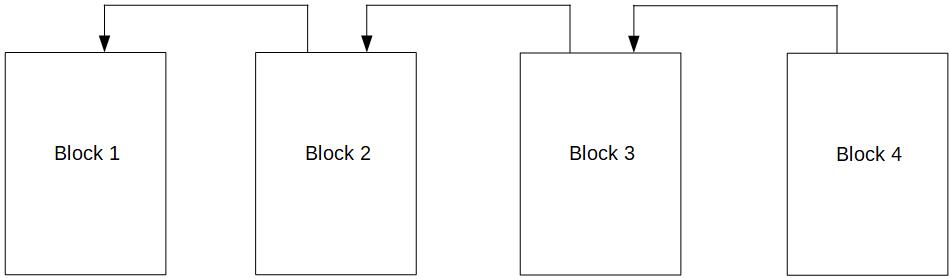
And now we say that a transaction can only reference a transaction that is part of a previous block. Do you remember the section where we said that Debora checks if Chris was allowed to spend Bob’s coin, and Bob was allowed to spend Alice’s coin? And that this was pretty difficult? Here, we have the solution.
Let’s assume Alice created a transaction where she sent a coin to Bob (more precisely, his address). Bob can now only spend this coin if Alice’s transaction is in a block that is part of the chain. If it is not in such a block all other nodes will ignore Bob’s transaction to Chris, because they would say that Bob doesn’t own this coin.
But this is only the first step to solving the double-spending problem.
Bob could actually create two chains. One chain with his transaction to Chris and one chain with his transaction to Deborah. Both chains would actually be “technically correct”. Basically, everybody could create its own chain in this setup. So, if anyone can add blocks whenever he likes, this leads to no consensus as it is easy to imagine. That’s why we have to restrict adding blocks in some way.
We do this by granting the right to add a block to certain users Ideally, this user selection process should choose another “block producer” every time, and it should be a random choice. Otherwise, such a user could abuse his power. This is where our consensus mechanism Proof of Work enters the stage.

 Register
Register Sign in
Sign in