Integrating Erasure Coding and Proof of Replication for Secure Decentralized Storage Systems
Decentralized storage systems use peer-to-peer networks and blockchain technology to distribute data among multiple nodes rather than relying on a single, central authority. By storing the data across a global network, these systems provide improved fault tolerance, transparency, and resilience compared to traditional cloud storage. Redundancy is a key design element in decentralized systems because network nodes can go offline unpredictably. Two primary redundancy strategies are:
- Replication: Storing multiple identical copies of data across different nodes.
- Erasure Coding: Splitting files into both data and parity fragments that enable data recovery despite fragment loss.
Storage proof mechanisms like Proof-of-Replication (PoRep), Proof-of-SpaceTime (PoSt), and Proof-of-Retrievability (PoR) further ensure data integrity and availability. Filecoin leverages a decentralized storage network that uses PoRep with replication; however, integrating PoRep with erasure coding remains underexplored. In this post, we explore a system combining PoRep and erasure coding, aimed to enhance data security and availability in decentralized storage.
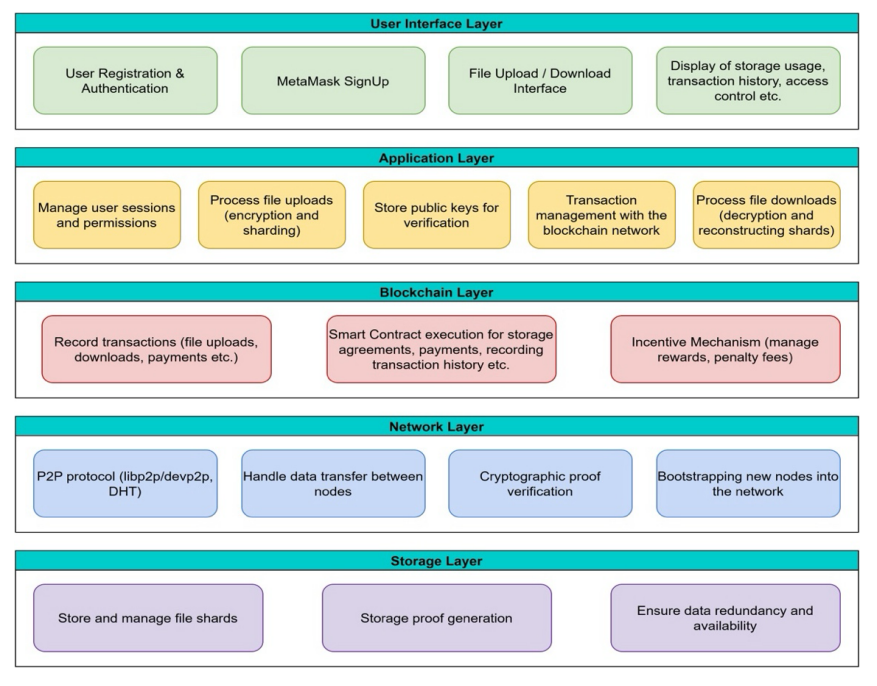
System Architecture
We propose a blockchain-based decentralized storage solution with a layered architecture:
- User Interface Layer: Allows users to upload and download files, select storage providers (based on factors like reputation or location), and interact seamlessly with the system.
- Application Layer: Encrypts uploaded files, applies erasure coding to split them into fragments, and distributes these fragments across multiple storage nodes.
- Blockchain Layer: Uses smart contracts to automate storage contracts, verify Proof-of-Replication storage proof submissions, and manage incentives or penalties for storage providers.
- Network Layer: Leverages a peer-to-peer protocol for communication and routing, distributing file fragments to the appropriate nodes and retrieving them as needed.
- Storage Layer: Consists of the storage nodes, which store data fragments and generate cryptographic proofs for verification on the blockchain.
Erasure Coding
Replication method simplifies file retrieval, but it is highly storage inefficient. On the other hand, erasure coding provides better storage efficiency and fault tolerance. It is mainly described by two numbers 𝑘 and 𝑛 where 𝑛 is the total number of fragments in which the original file is split, and 𝑘 (also known as data fragments) is the required number of fragments to reconstruct the original file. The system can tolerate losing up to 𝑚 fragments (also known as parity fragments defined as ![]() ). Reed-Solomon encoding scheme is a widely used erasure coding method due to its computational efficiency. Key metrics to understand erasure coding includes:
). Reed-Solomon encoding scheme is a widely used erasure coding method due to its computational efficiency. Key metrics to understand erasure coding includes:
- Expansion factor (𝒙): The ratio of how much data size increases due to erasure coding. It is calculated as:
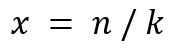
- Storage overhead: The additional storage space required apart from the original data size to achieve redundancy. It is calculated as (in percentage):
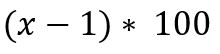
Suppose we have a file of size b bytes and we apply (k,n) erasure code, then each erasure
fragment will be approximately of b/k bytes in size. As an example,
- Consider a file of size 100 MB with n = 14, k = 10
- Each fragment will be split into 100/10 = 10 MB along with 4 additional 10 MB fragments as parity fragments for redundancy.
- The system fault tolerance would be m = 4
- Expansion factor is calculated as x = n/k = 1.4
- Storage overhead would be: (1.4 – 1)*100 = 40%
Whereas, in replication method, to store a file of 100 MB with replication factor 4, then we would need a total of 5 copies of the original file. The storage overhead would be (100*5)/100 = 5x.
By distributing fragments across nodes, erasure coding significantly reduces storage overhead
compared to the replication method. Users can choose the 𝑘 and 𝑚 values to balance cost, durability, and fault tolerance based on their specific needs.
Proof of Replication
Proof of Replication (PoRep) is a storage proof mechanism which uniquely encodes stored data, ensuring each storage provider allocates distinct physical space for a file. This mechanism prevents data deduplication and binds the replica to the provider’s identity, by providing resistance towards Sybil and generational attacks while maintaining data integrity and correctness. The provider stores data D, in a sector, where a computationally intensive sealing process transforms D into a uniquely encoded replica, R. The PoRep process has following phases:
- Encoding: This process splits data D into
 32-byte nodes arranged across Nlayers in a Stacked Depth Robust Graph (DRG) structure. Nodes in layer l are connected nodes in layer l + 1 through a bipartite expander algorithm. Within each layer
32-byte nodes arranged across Nlayers in a Stacked Depth Robust Graph (DRG) structure. Nodes in layer l are connected nodes in layer l + 1 through a bipartite expander algorithm. Within each layer  deterministic DRG parents are generated using Bucket Sampling algorithm. For l > 0, expander parent nodes are generated from layer l – 1
deterministic DRG parents are generated using Bucket Sampling algorithm. For l > 0, expander parent nodes are generated from layer l – 1 All nodes are then labeled sequentially using SHA-256, producing 254-bit field elements. A Merkle tree built over these labeled nodes yields the commitment (CommC), while the final layer’s labels form an encoding key K. Each node Di combines with its corresponding key Ki via prime field addition to produce the replica Ri
All nodes are then labeled sequentially using SHA-256, producing 254-bit field elements. A Merkle tree built over these labeled nodes yields the commitment (CommC), while the final layer’s labels form an encoding key K. Each node Di combines with its corresponding key Ki via prime field addition to produce the replica Ri - Replication: This is the entire process of transforming a sector D into a uniquely encoded replica R by assigning it a unique ReplicaID, which is generated using provider’s ID, sector ID and commitment CommD derived from unsealed sector data. This ensures that R cannot be reproduced without the original data and related commitments, providing secure verifiability through the generated commitments.
- Merkle Tree and Proof Generation: A Merkle tree TreeR built over the encoded nodes
 produces a root CommR, serving as a cryptographic commitment. This structure enables efficient proof generation and data verification for dedicated storage. PoRep proof includes the encoded data, the storage provider’s identity, and sealing metadata, which is then compressed using a succinct cryptographic method. Finally, it is submitted to the blockchain, certifying that the data is stored uniquely and securely.
produces a root CommR, serving as a cryptographic commitment. This structure enables efficient proof generation and data verification for dedicated storage. PoRep proof includes the encoded data, the storage provider’s identity, and sealing metadata, which is then compressed using a succinct cryptographic method. Finally, it is submitted to the blockchain, certifying that the data is stored uniquely and securely.
Users can choose providers based on factors like reputation, location, or available space, optimizing cost, performance, and security. Each provider secures its fragment and produces a storage proof for the data it is storing. These proofs are validated on the blockchain and any dishonest behaviour or incorrect proof submission by providers is penalized and for a correct proof, they are rewarded which motivates them to behave honestly. By combining erasure coding with Proof of Replication, bandwidth overhead is lowered, and retrieval speed is improved without excessive storage overhead.
References
- N, Racin (2023): Improving Data Availability in Decentralized Storage Systems, University of Stavanger, Norway. ISBN: 978-82-8439-158-8.
- Protocol Labs (2017): “Filecoin: A Decentralized Storage Network”, [Online] https://filecoin.io/filecoin.pdf. [Accessed: 16.01.2025].
- Shacham, H., Waters, B. (2013): Compact Proofs of Retrievability. J Cryptol 26, pg. no. 442–483.
- Storj Labs (2016): “Storj: A Peer-to-Peer Cloud Storage Network,” [Online] https://github.com/storj/whitepaper. [Accessed: 18.01.2025].
- B. Juan, D. David, G. Nicola (2017). “Proof of Replication”, [Online] https://filecoin.io/proof-of-replication.pdf. [Accessed 06.08.2024].

 Register
Register Sign in
Sign in
1 Comment
Comments are closed.